Introduction to Active Learning

Published on
Introduction
Active learning is a machine learning technique that allows you to train a model with less labeled data. It is particularly useful when you have a large amount of unlabeled data and only a small amount of labeled data. In this guide, we’ll walk you through the basics of active learning and show you how to get started with using Oslo and the Oslo SDK to improve the performance of your machine learning models.
In this tutorial we will:
Start with the motorcyle and bicycle dataset we used in the How to Annotate and Train a YOLOv11 Model With Oslo guide.
We will then select the most informative samples from our unlabeled data and add them to our training set using the Oslo SDK.
We will create an active learning loop and compare our model performance against each other with an independent test set.
Our original dataset consists of images of motorcycles and bicycles. We have annotated these images with bounding boxes around the motorcycles and bicycles. We have used this dataset to train a YOLOv11 model using Oslo’s annotation and training tools. The number of images in the original dataset is a modest 153 images.
Unlabeled dataset
We have a large amount of unlabeled data that we would like to use to improve the performance of our model. This dataset consists of 10374 images of motorcycles and bicycles. We have not annotated these images, so they are considered unlabeled data.
This is available to download from here
Inference on the unlabeled dataset
The first step is to infer on the unlabeled dataset using the model we trained with the original dataset. This will allow us to get predictions for each image in the unlabeled dataset. We will use these predictions to select the most informative samples for our active learning process.
Lets first, infer on all the 10k images and order them by conidence score, we will then select the first 100 images with the lowest confidence scores.
import glob
from ultralytics import YOLO
model = YOLO("./scratch/models/bikeweights.pt")
# Directory containing images
dataset_location = "./scratch/active/unlabelled"
image_paths = glob.glob(os.path.join(dataset_location, '*.jpg'))
# Array to store images with low confidence predictions
images_with_conf = []
# Loop through the images and perform inference
for image_path in image_paths:
result = model(image_path)[0]
# Get minimum confidence for this image
min_conf = float('inf') if len(result.boxes.conf) == 0 else result.boxes.conf.min().item()
# Store tuple of (min_confidence, image_path, result)
images_with_conf.append((min_conf, image_path, result))
# Sort by minimum confidence (ascending order)
sorted_images = sorted(images_with_conf, key=lambda x: x[0])
# Take first 100 results
top_100 = sorted_images[:100]
The next step is to upload these images an annotations to Oslo. We will use the Oslo SDK to upload the images and annotations to our project on Oslo. We will then reannotate the images if necessary using the annotation editor and add them to our training pipeline.
from oslovision import OsloVision
api = OsloVision("your_api_key")
project_identifier = "your_project_identifier"
# Now upload images and their annotations
for min_conf, img_path, result in top_100:
# Upload the image
with open(img_path, "rb") as img_file:
image_data = api.add_image(project_identifier, img_file)
print(f"Added image: {os.path.basename(img_path)} (ID: {image_data['id']})")
# Add all annotations for this image
for box in result.boxes:
# Convert YOLO's xyxy format to x,y,width,height
bbox = box.xyxy[0].tolist()
x0 = bbox[0]
y0 = bbox[1]
width_px = bbox[2] - bbox[0]
height_px = bbox[3] - bbox[1]
# Get class name
class_id = int(box.cls)
class_name = result.names[class_id]
# Create annotation
try:
annotation = api.create_annotation(
project_identifier,
image_data['id'],
class_name,
x0=x0,
y0=y0,
width_px=width_px,
height_px=height_px,
)
print(f" Created annotation: {annotation['id']} ({class_name}, conf={float(box.conf):.3f})")
except Exception as e:
print(f" Error creating annotation for {os.path.basename(img_path)}: {str(e)}")
print(f"Completed processing {os.path.basename(img_path)}\n")
After uploading the images and annotations to Oslo you will see something like this:
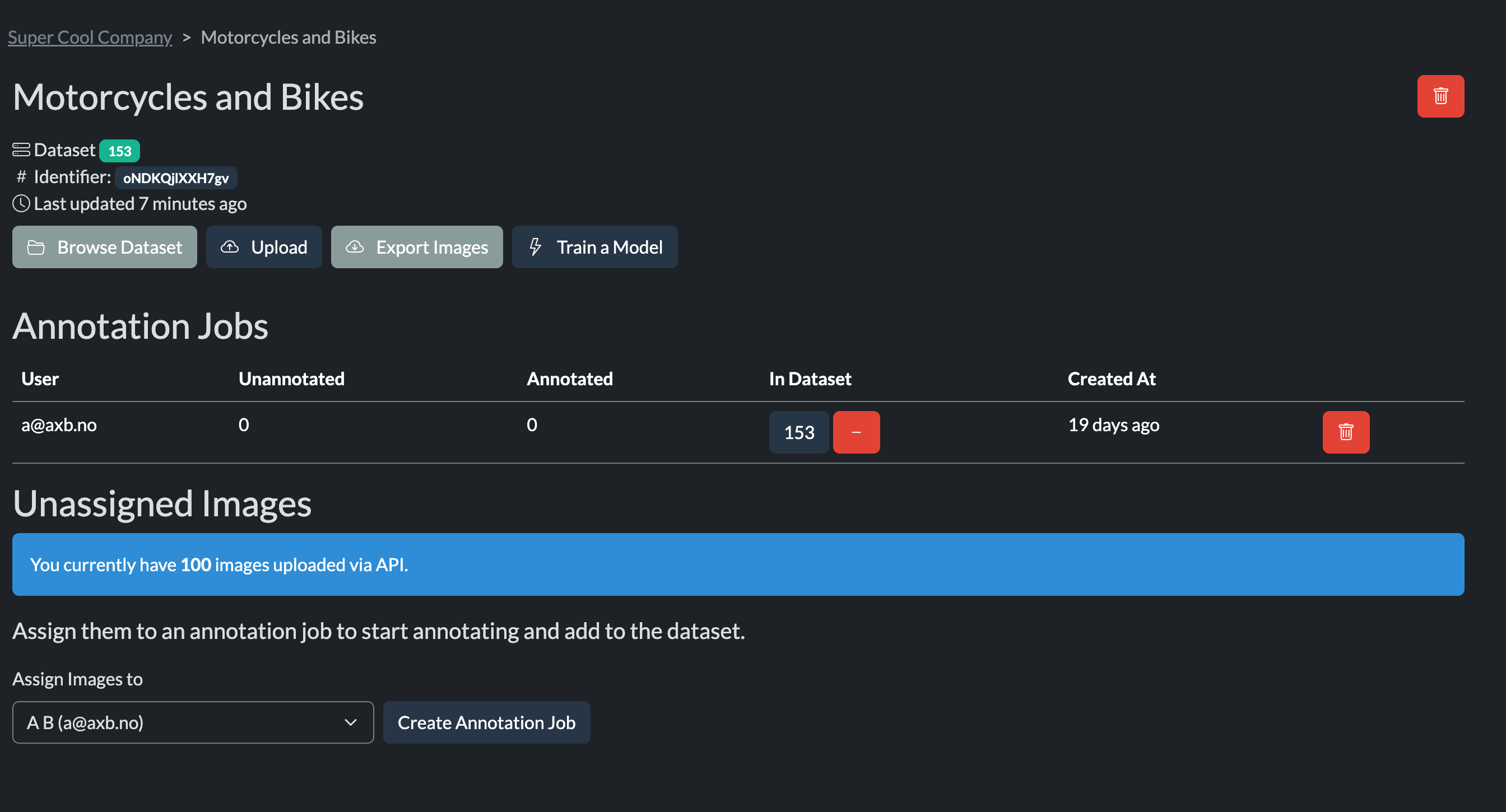
After api upload
You can assign the images to an annotator (often just yourself) and start annotating the images. Once you have annotated the images, you can export the annotations and use them to retrain your model.
The training process is described in the How to Annotate and Train a YOLOv11 Model With Oslo guide.
## Random sampling to create a test set
We will now create a test set by randomly sampling 100 of the images from the unlabelled data, then uploading them to oslo, annotating and exporting. We will use this test set to evaluate the performance of our models trained with the active learning data.
```python
import glob
import os
import random
# Directory containing images
dataset_location = "/home/pyrat/scratch/active/unlabelled"
image_paths = glob.glob(os.path.join(dataset_location, '*.jpg'))
# Randomly select 100 images
random_100_paths = random.sample(image_paths, min(100, len(image_paths)))
# Upload the images to Oslo
from oslovision import OsloVision
api = OsloVision("your_api_key")
project_identifier = "your_project_identifier"
for img_path in random_100_paths:
# Upload the image
with open(img_path, "rb") as img_file:
image_data = api.add_image(project_identifier, img_file)
print(f"Added image: {os.path.basename(img_path)} (ID: {image_data['id']})")
We can now annotate these images using the Oslo annotation editor and export the annotations to create a test set.
Comparing the models
# download the test set and run models on them comparing the results
from oslovision import OsloVision
import os
api = OsloVision("your_api_key")
project_identifier = "your_project_identifier"
test_export_dir = "/home/pyrat/scratch/active/test_set_unseen"
os.makedirs(test_export_dir, exist_ok=True)
dataset_path = api.download_export(project_identifier, 1, test_export_dir)
dataset_yaml = os.path.join(dataset_path, "data.yaml")
model_path = "./scratch/models/bikeweights1.pt"
!yolo val model=$model_path data=$dataset_yaml
model_path = "./scratch/models/bikeweights2.pt"
!yolo val model=$model_path data=$dataset_yaml
Let have a look at the results:
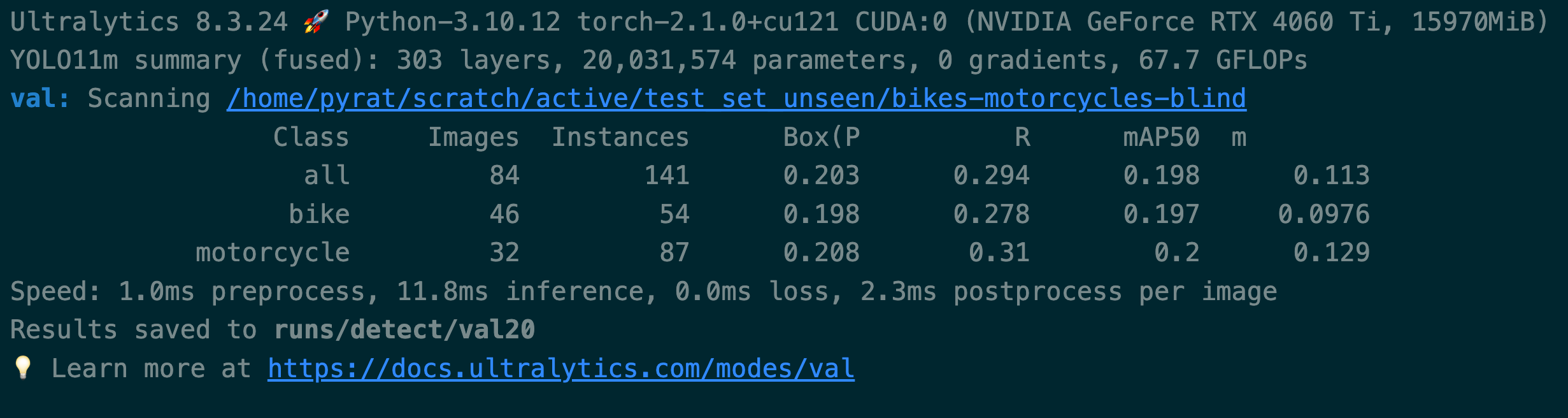
Pre active learning
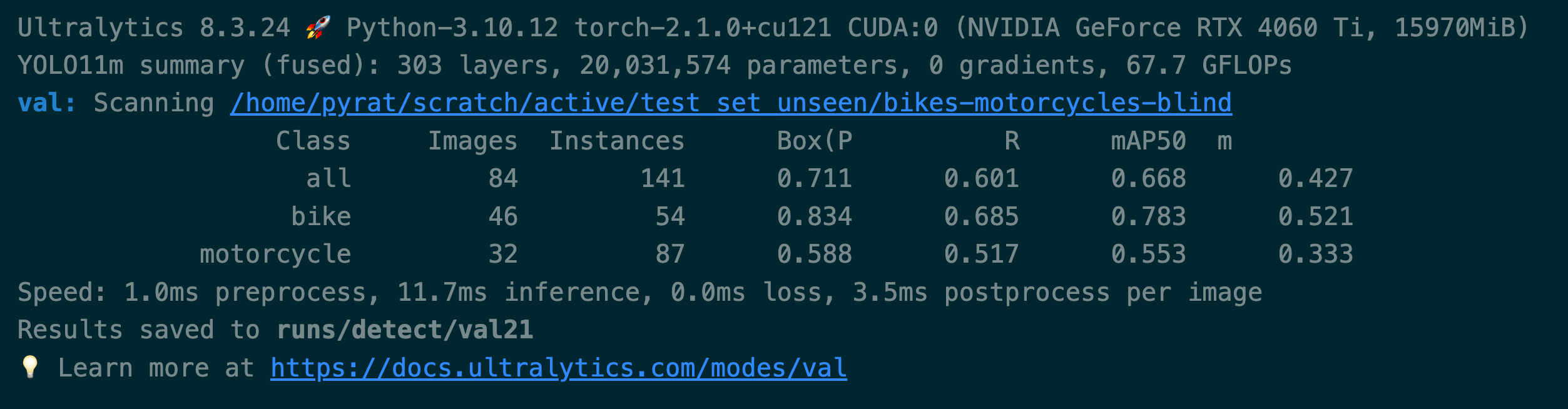
Low confidence training
As you can quickly see we have a huge improvement in the performance of the model after training with the active learning data. The model trained with the active learning data has a much higher mAP score than the model trained with the original training data alone.
This is the power of active learning. By selecting the most informative samples from our unlabeled data and adding them to our training set, we were able to improve the performance of our model without having to label all of the data. Work smarter, not harder!
Lets try to improve the model further by selecting 100 images without detections and adding them to our active learning loop. (Upload to oslo, annotate, retrain, evaluate). Remember to use the most recent model weights for the inference step.
import glob
from ultralytics import YOLO
import os
import random
model = YOLO("/home/pyrat/scratch/models/bikeweights2.pt")
# Directory containing images
dataset_location = "/home/pyrat/scratch/active/unlabelled"
image_paths = glob.glob(os.path.join(dataset_location, '*.jpg'))
images_without_results = []
# Loop through the images and perform inference
for image_path in image_paths:
result = model(image_path)[0]
# If no detections, add to list
if len(result.boxes) == 0:
images_without_results.append(image_path)
print(f"Total images processed: {len(image_paths)}")
no_det_100 = images_without_results[:100]
from oslovision import OsloVision
api = OsloVision("your_api_key")
project_identifier = "your_project_identifier"
# Now upload images and their annotations
for img_path in no_det_100:
# Upload the image
with open(img_path, "rb") as img_file:
image_data = api.add_image(project_identifier, img_file)
print(f"Added image: {os.path.basename(img_path)} (ID: {image_data['id']})")
Lets retrain the model and evaluate the performance.
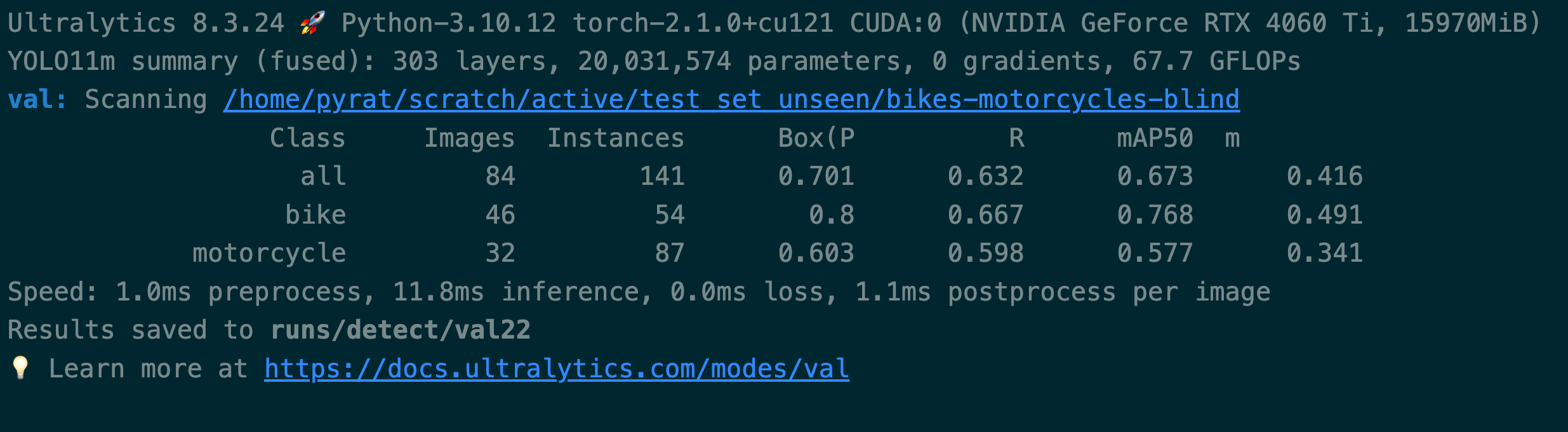
No detections training
The results here are not as good as the previous step, but we have still managed to improve the performance of the model by adding the most informative samples from our unlabeled data to our training set. I would try more interations of low confidence detections, specifically form motorcycles, as the model seems to be struggling with these.
Conclusion
In this guide, we have introduced you to the concept of active learning and shown you how you can use it to improve the performance of your machine learning models. By selecting the most informative samples from your unlabeled data and adding them to your training set, you can train a model with less labeled data and achieve better performance.