What Is Precision and What Is Recall When Training Vision AI Models

Published on
Precision and recall are two essential metrics for evaluating the performance of computer vision models. Understanding these concepts is crucial for AI developers and data scientists aiming to build accurate and reliable models.
In the realm of machine learning, precision and recall provide a more nuanced view of model performance than accuracy alone. By delving into these metrics, practitioners can gain valuable insights into their models’ strengths and weaknesses, enabling them to make informed decisions during the development process.
This article will explore the fundamentals of precision and recall, their significance in computer vision tasks, and how they can be leveraged to optimize model performance. We will also discuss the trade-offs between these metrics and how they can be combined to create a balanced evaluation approach.
What are Precision and Recall?
Precision and recall are two critical metrics used to evaluate the performance of machine learning models, particularly in the context of computer vision. Precision measures the accuracy of positive predictions, answering the question: “Of all instances labeled as positive, how many were actually positive?” In other words, precision focuses on the model’s ability to minimize false positives—instances incorrectly identified as positive.
$$\text{Precision} = \frac{TP}{TP + FP}$$
Where:
- TP (True Positives): The number of correctly identified positive instances.
- FP (False Positives): The number of instances incorrectly classified as positive.
On the other hand, recall measures the completeness of positive predictions, addressing the question: “Of all actual positive instances, how many were correctly identified?” Recall emphasizes the model’s capability to minimize false negatives—instances that should have been identified as positive but were missed.
$$\text{Recall} = \frac{TP}{TP + FN}$$
Where:
- TP (True Positives): The number of correctly identified positive instances.
- FN (False Negatives): The number of actual positive instances that were incorrectly classified as negative.
A good way to visualize these two formulas is the following cake analogy:
- Precision: Imagine you have a cake, and you want to serve it to your friends. Precision is like ensuring that every slice you serve is actually cake. If you accidentally serve a slice of cardboard instead of cake, that’s a false positive.
- Recall: Now, recall is about making sure you serve all the cake. If you leave some cake in the kitchen and don’t serve it, that’s a false negative.
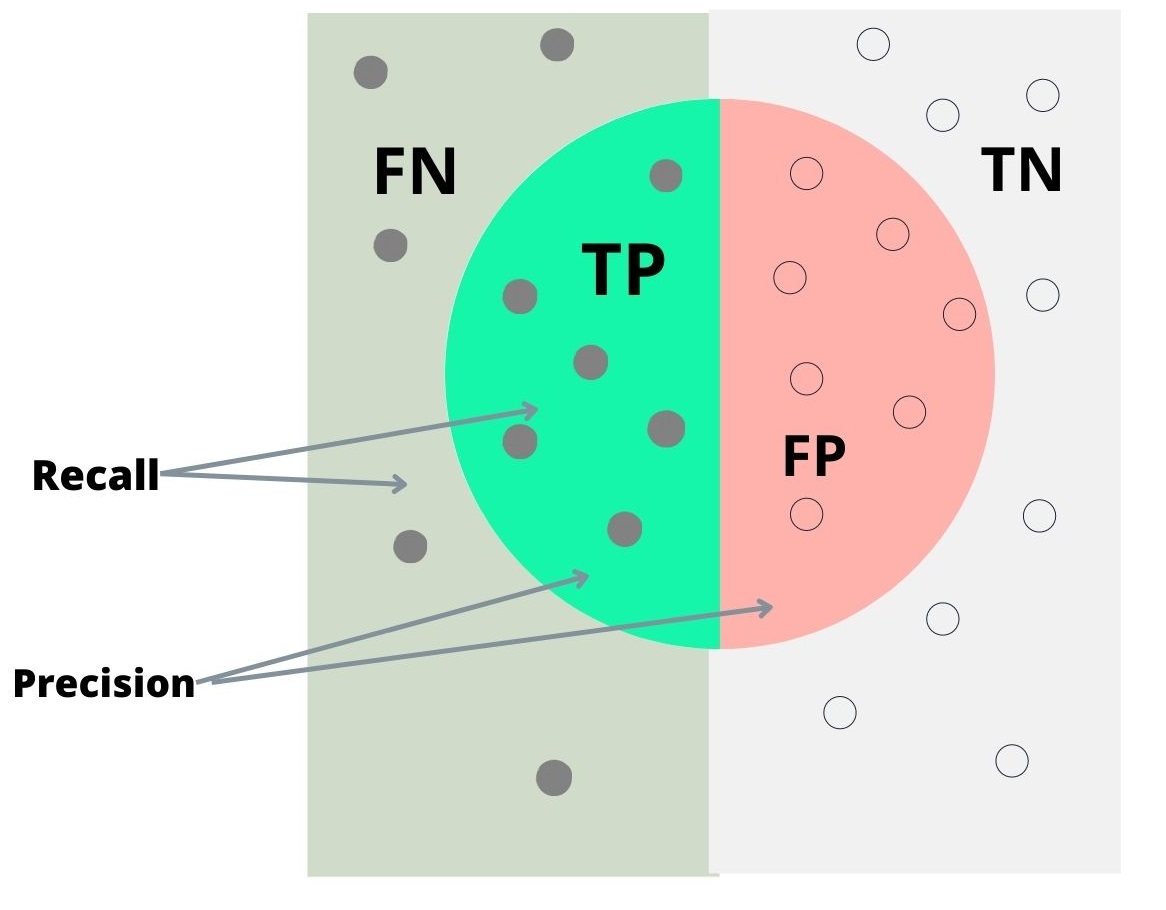
Precision and Recall Formulas Visualized
The Importance of Precision and Recall in Computer Vision
In computer vision tasks, such as object detection, image segmentation, and facial recognition, precision and recall play a vital role in assessing model performance. These metrics provide a more comprehensive understanding of a model’s capabilities than accuracy alone, as they consider both the correctness and completeness of predictions.
High precision is crucial in scenarios where false positives can have significant consequences, such as in medical diagnosis or autonomous driving. In these cases, incorrectly identifying a benign tumor as malignant or misclassifying a pedestrian as a road obstacle can lead to unnecessary interventions or potentially dangerous situations.
Conversely, high recall is essential in applications where missing a positive instance can be detrimental, such as in surveillance systems or safety-critical environments. Failing to detect a security threat or overlooking a defective product on an assembly line can have severe repercussions.
By carefully examining precision and recall, AI developers and data scientists can gain valuable insights into their models’ performance and make informed decisions to optimize them for specific use cases. Tools like Oslo, which provide comprehensive dataset management and labeling capabilities, can help streamline the process of evaluating and refining computer vision models based on these metrics.
The Confusion Matrix: Evaluating Model Performance
A confusion matrix provides a detailed framework for assessing the performance of classification models. It organizes predictions into four categories that define the model’s strengths and weaknesses, offering a granular view that supports targeted improvements. By examining these categories, developers gain insights into the specific areas where their models excel or falter.
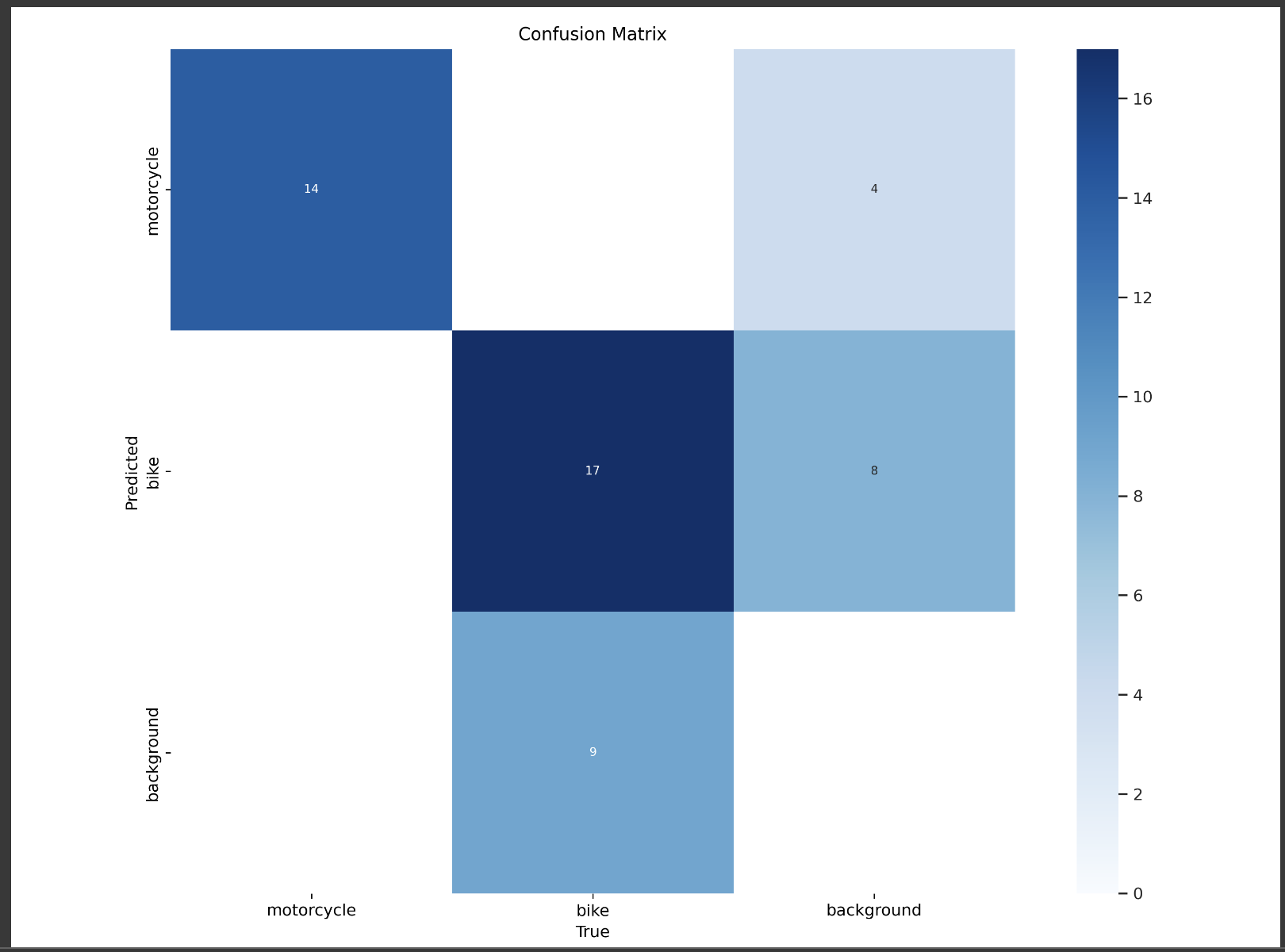
Confusion Matrix Example
Components of the Confusion Matrix
- True Positives (TP): Correctly identified positive instances, signifying the model’s effectiveness in recognizing true positive cases.
- False Positives (FP): Instances wrongly classified as positive, known as Type I errors, reflecting over-predictions of the positive class.
- True Negatives (TN): Correctly identified negative instances, demonstrating accurate identification of the negative class.
- False Negatives (FN): Instances wrongly classified as negative, or Type II errors, indicating missed positive cases.
Each category within the confusion matrix contributes to a comprehensive evaluation of model performance. True positives and true negatives confirm the model’s predictive accuracy, while false positives and false negatives expose areas needing refinement. This breakdown aids in systematically enhancing models by addressing specific prediction errors.
In the example above, you can see that the bike class performs worse than the motorcycle class both with precision and recall. Including a number of false positives and false negatives. Improve the number and quality of bike annotation in your dataset and retrain.
Precision: Minimizing False Positives
Precision acts as a crucial measure in assessing how accurately a model identifies true positive instances among its positive predictions. This metric calculates the proportion of correctly identified positive results out of all the instances flagged as positive by the model. Achieving high precision implies the model effectively minimizes incorrect positive identifications, thereby enhancing the reliability of its predictions.
In domains where the implications of false positives are substantial, precision holds significant value. For instance, in the medical field, a false positive could lead to unwarranted treatments and patient anxiety. Similarly, in email filtering systems, misclassifying legitimate messages as spam can result in missed communications. Thus, elevating precision is paramount in these contexts to mitigate the adverse effects of inaccurate positive detections.
Precision in Object Detection
In the realm of computer vision, precision evaluates the accuracy of object localization within images, particularly through bounding box predictions. This involves assessing how consistently detected objects correspond to the actual objects in the image. A model boasting high precision will precisely identify target objects, minimizing the misclassification of irrelevant elements.
- Accuracy of bounding boxes: Precision evaluates the model’s capability to correctly delineate the boundaries of objects, ensuring it distinguishes between overlapping or closely placed entities.
- Reduction of false detections: By focusing on improving precision, developers can decrease the frequency of erroneous object identifications, thus bolstering the model’s overall reliability.
Recall: Minimizing False Negatives
Recall stands as a pivotal metric in evaluating a model’s thoroughness in identifying all relevant positive instances, concentrating on the reduction of false negatives. This metric quantifies the proportion of actual positive cases that the model successfully identifies. High recall is indispensable in scenarios where overlooking a positive instance carries significant risks, ensuring comprehensive detection of critical elements.
In high-stakes fields like medical imaging and disaster response, the necessity of recall becomes clear. Overlooking a minute anomaly in a medical scan or missing a sign of distress in disaster imagery can lead to grave consequences. Thus, enhancing recall is paramount to guarantee that no essential details are missed, ensuring a more reliable and responsive system. By prioritizing recall, developers can better assure that every crucial instance receives attention, thereby reducing the possibility of oversight in critical environments.
The Precision-Recall Trade-off
Managing the interplay between precision and recall requires a nuanced strategy, as these metrics often counterbalance each other. Improving precision can lead to reduced recall, and vice versa. This dynamic necessitates a keen understanding of the specific context and error costs associated with any given application.
Balancing Precision and Recall
Achieving a harmony between precision and recall is essential for fine-tuning model performance. The ideal balance is contingent on the unique requirements of the task. For instance, in automated emergency detection systems, ensuring comprehensive detection with high recall might be prioritized, allowing for some false alarms. Meanwhile, in email filtering, where false positives could result in lost communications, precision may be more critical.
- Task-oriented priorities: Each application has its own demands that dictate the relative importance of precision versus recall. Aligning model objectives with these demands ensures relevance and effectiveness.
- Error cost analysis: Evaluating the repercussions of false positives versus false negatives guides the adjustment of precision and recall. In scenarios where the cost of one error type outweighs the other, finding the right balance becomes crucial.
Utilizing Precision-Recall Curves
Precision-recall curves offer a graphical representation of the trade-offs between these metrics, providing a clear view of model performance across different thresholds. By charting precision against recall, these curves assist in determining the most suitable threshold that aligns with the application’s goals.
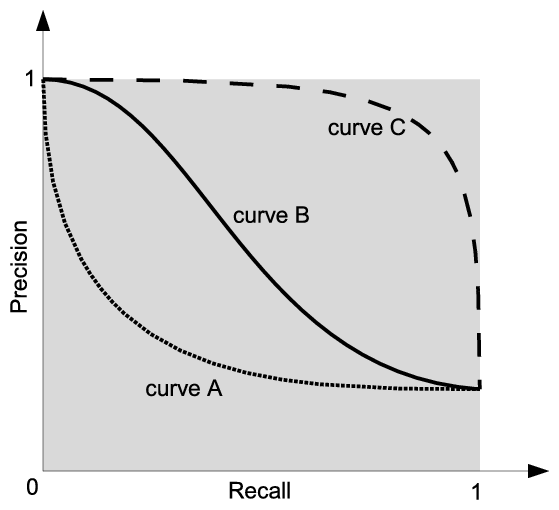
Precision-Recall Curve Example
In the graph above you can see three curves, curve A shows a poorly performing model, curve B show a model with medium performance where Curve C shows a model with high performance. The area under the curve (AUC) is a good indicator of the model’s performance. The higher the AUC, the better the model.
- Threshold experimentation: Precision-recall curves facilitate the exploration of various thresholds to locate the balance where precision meets recall optimally. This involves interpreting the curve to find a threshold that satisfies application-specific requirements.
- Data-driven insights: These curves empower developers with a comprehensive understanding of how threshold adjustments impact model outcomes. This insight aids in making informed decisions that align with desired performance objectives.
Strategically managing the precision-recall trade-off involves tailoring models to the distinct context of each application, using precision-recall curves as a tool for decision-making. Through careful analysis and adjustments, developers can optimize models to perform effectively in their intended settings, delivering robust Vision AI solutions.
Combining Precision and Recall: F1 Score
The F1 score serves as an essential metric for evaluating machine learning models, particularly when precision and recall require a harmonious balance. By representing the harmonic mean of precision and recall, the F1 score consolidates these metrics into a singular value, offering a comprehensive view of model performance. This makes it invaluable in contexts where striking a balance between precision and recall is more crucial than prioritizing one over the other.
Calculating the F1 Score
The F1 score is derived using the formula:
$$\text{F1} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}$$
Where:
- Precision: The proportion of true positive predictions among all positive predictions.
- Recall: The proportion of true positive predictions among all actual positive instances.
- F1 Score: The harmonic mean of precision and recall, providing a balanced evaluation of model performance.
This calculation method ensures that neither precision nor recall disproportionately influences the score, providing a balanced perspective on the model’s predictive capability. The harmonic mean’s sensitivity to low values ensures that both metrics must be strong for a high F1 score, preventing scenarios where a model excels in one metric while faltering in the other.
- Balanced representation: The F1 score equally considers both precision and recall, ensuring incremental improvements in one do not overshadow deficiencies in the other. This equilibrium is vital in situations where both false positives and false negatives carry significant implications.
- Holistic evaluation: As a single metric, the F1 score simplifies the comparison of models, especially across diverse tasks or datasets where precision and recall alone may not fully capture performance nuances.
When to Use the F1 Score
The F1 score is particularly advantageous in applications where achieving a balanced performance between precision and recall is imperative. It streamlines the decision-making process by providing a clear metric that reflects two critical dimensions of model evaluation, facilitating the comparison and selection of models.
- Complex evaluation scenarios: In settings with intricate trade-offs where both false positives and false negatives could have substantial impacts, the F1 score offers a well-rounded assessment. For example, in security systems, both types of errors could lead to serious consequences, necessitating a balanced evaluation.
- Guidance in model selection: When choosing among multiple models, the F1 score helps identify those that maintain a reasonable balance between precision and recall. It proves particularly useful in the early stages of model development, guiding refinement efforts towards balanced improvements.
However, when the costs associated with false positives and false negatives differ significantly, relying solely on the F1 score may not be the best approach. In such instances, a more detailed analysis of individual precision and recall metrics, along with domain-specific considerations, ensures that the selected model aligns with the application’s specific needs and priorities.
Applying Precision and Recall in Computer Vision Tasks
Object Detection
In the realm of object detection, precision and recall serve as pivotal metrics for evaluating model performance. Precision assesses how accurately models distinguish between objects of interest and non-target elements in a scene. This ensures the model’s predictions are relevant and minimizes the chances of mistakenly classifying irrelevant background as objects, which is critical for applications like autonomous navigation where clarity in object identification is paramount.
- Detection Clarity: High precision focuses on correctly identifying objects without confusion, which is essential for applications requiring precise environmental interaction.
- Minimization of Noise: Precision ensures that detections are significant and not overwhelmed by irrelevant background elements, allowing for accurate decision-making in dynamic environments.
Recall, conversely, measures the model’s ability to identify all pertinent objects within an image, ensuring comprehensive recognition capability. This comprehensive detection is crucial in fields such as wildlife monitoring, where capturing every animal within a frame contributes to accurate ecological assessments.
Image Segmentation
Precision and recall in image segmentation are pivotal for evaluating pixel-level accuracy and completeness. Precision focuses on ensuring that each pixel assigned to an object truly belongs to that object, reducing misclassification in segmented images. This precision is vital in medical imaging, where the accuracy of delineating anatomical structures can significantly impact diagnostic decisions.
- Boundary Accuracy: Precision in image segmentation ensures that object edges are correctly defined, maintaining the integrity of segmented regions.
- Detail Accumulation: High precision supports maintaining the granularity of intricate visual elements, crucial for applications relying on detailed visual information.
Recall in image segmentation emphasizes the model’s capacity to capture all relevant pixels, ensuring no significant segments are overlooked. In satellite imagery analysis, this exhaustive detection supports the accurate mapping of land features, contributing to informed environmental insights.
Specialized Applications
In specialized applications such as facial recognition or medical image analysis, precision is often prioritized to reduce false positives. Ensuring that models accurately recognize individuals or diagnose conditions without misclassification is vital in these domains, where errors can lead to privacy infringements or incorrect treatments. Meanwhile, in settings like autonomous driving and surveillance, high recall is critical to ensure that all relevant entities are detected, avoiding missed detections that could compromise safety or security measures.
Conclusion
As you embark on your computer vision journey, understanding precision and recall will empower you to build models that deliver reliable, accurate results. By leveraging these metrics to optimize your models, you can unlock the full potential of Vision AI across a wide range of applications. If you’re ready to streamline your dataset management and model evaluation process, we invite you to Sign up for a free account to explore Oslo’s Vision AI platform and experience the power of precision and recall firsthand.